马克莱姆面试两部分:模拟和实验,他们能合作吗?


第二我们的独家访谈系列蓝脑计划”的创始人和主任教授亨利·马克拉姆,我们将讨论如何模拟大脑神经科学中受益。在网上,informatics-based方法已经彻底改变了生命科学在过去的三十年里,但使用这些方法来绘制大脑的神经生物学是一个挑战。我们听到马克拉姆的挑战是一个值得的原因,在计算机技术如何改善神经科学的再现性和马克拉姆的蓝脑计划如何使用超级计算资源。找到更多关于我们的马克拉姆访谈系列在这里。
Ruairi Mackenzie (RM):大脑是如此复杂,我们所知甚少,甚至如何开始建立一个数字拷贝?
亨利·马克莱姆(HM):我们需要更多的数据来建立和全面测试的数字重建大脑和仍确实有许多尚未解决的难题大脑是如何工作的。然而,这是错误的认为这些早期的数字拷贝的大脑作为构建只有当你有一些你的困惑(即所有的数据和知识)。我们已经开发出这种方法正是因为我们没有,我们不认为我们可以得到,所有数据。我们的方法有助于识别和预测丢失的碎片当我们试图建立它。这样的工作方式是,我们先务实收集什么数据是可用的(如在大脑电路)。这是非常稀疏的数据(例如,几个类型的神经元之间的突触的数量)和许多缺失的空白(如多少所有类型的神经元之间突触存在)。然后,我们使用数据科学分析数据和neuroinformatics工具识别的原则如何彼此相关的所有数据(例如,当输入一个神经元连接型B,它使用五个突触连接型C型,它使用平均10突触)。然后建立一个算法,这些生物规则。该算法并在所有的神经元之间形成突触连接根据这些规则。然后我们测试算法通过比较新数据的重建,我们离开,这不是用来构建算法(如两个其他类型的神经元之间突触的数量)。如果它通过了测试,那么我们继续构建更多的生物。如果失败了,我们回去试着理解错了什么我们的理解(例如神经元如何形成连接的),问我们是否可能需要更多的数据。我们测量在我们需要的时候出现。
实际上,它令人兴奋当模型失败,因为我们知道,我们是在科学的前沿,因为我们已经考虑所有可用的数据和所有当前理论的神经元连接,它仍然失败。这意味着有一些意外的发生。有时,这意味着回到实验室,做新的实验,因为数据可能是错误的。有时这意味着我们的理解和理论数据是错误的。所以我们进步了解每一次我们可以伪造模型。通过运行这个循环多次,我们越来越接近生物学和增加我们理解大脑是如何设计的。这允许我们做出更多的准确的预测的失踪,继续更困难的差距在我们的数据和知识。
这种方法不能替代实验,它只是加速发现数据并填写我们的差距在我们的知识。我们遵循这个过程严格离子通道的构建模型,神经元突触,电路,大脑区域并将跟随它建造的第一份草稿拷贝整个老鼠大脑。
RM:为什么在网上模型在神经科学有利吗?
嗯:在实验神经科学,一个可以访问只有一个非常小的比例的生物机制和理论神经科学,一个抽象的生物机制;在这两种方法,很难得到详细机制大脑的现象。在模拟神经科学,一个使用生物忠实的脑组织进行重建在网上(而不是在活的有机体内和在体外)实验可以访问所有的生物机制。提供了模型是接近实际的大脑的复制品,他们表现出人想研究的现象,然后详细的生物机制参与现象可以被识别。
但也有很多其他的原因。
著名神经科学家,·拉蒙-卡哈尔,开始在100多年前用铅笔绘制每个神经元,但是今天我们可以使用超级计算机构建大脑以数字形式。它实际上是最系统的数据组织方式,填满我们的数据的巨大差距,测试我们的知识,使我们的预测还不知道。
让我们想象一下,一个人可以操作和实验室测量大脑的方方面面;任何动态变化的基因、分子、神经元、突触,大脑区域等。它显然是更好的执行比生物实验在网上实验。然而,我们是光年无法在实验室。,即使这个假设的场景曾经可能,我们还是希望将这些数据放到一个忠实的数字拷贝的大脑,所以我们可以在许多不同的方式探索。
我看到模拟神经科学来获得一个完整的大脑的地图。映射大脑不是同样的挑战,人类基因组的映射。映射大脑需要描述许多不同级别的大脑,所有的所有元素之间的相互作用,以及他们如何随开发、经验、老化、菌株、物种,性别和大量的疾病。我认为是不可能的,我们不需要,衡量一切(这并不意味着我们应该停止实验)。模拟神经科学提供了一个解决方案——预测大多数它不可避免的有限样本的数据。
此外,这样一个模型将提供一个数学的描述大脑的方方面面。只有当我们能够捕获,在数学方面,每一个组件,交互和紧急现象在大脑中,我们能真正声称我们理解大脑。只有当我们可以重现世界和经验通过运行这些数学公式和算法,得到确凿的证据证明,我们会理解。
模拟神经科学也是一个强大的工具来测试大脑的理论。在神经科学中,我们有许多理论对大脑结构和功能的各种各样的方面,我们没有一个系统化、标准化的方式来测试理论。模型不是生物学上准确的大脑可以极大地有助于拟合数据和探索概念但不能要求测试时大脑的一个理论模型不包含大脑包含什么。
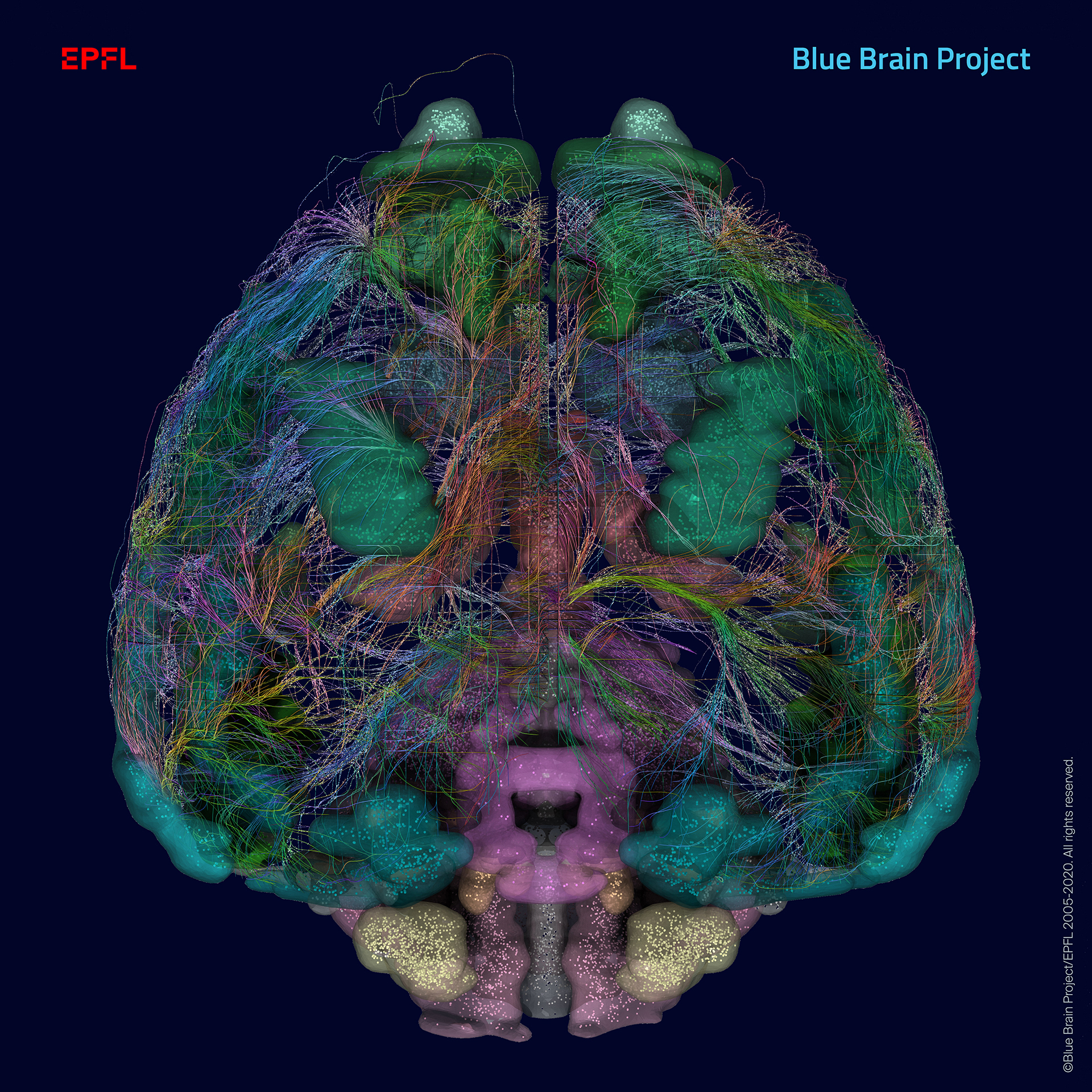
老鼠的大脑区域的脑图谱,显示单个细胞(点)和互联的白质纤维(由艾伦脑科学研究所)。信贷:版权©2005 - 2020蓝脑计划/欧洲。保留所有权利。
模拟神经科学也带来其他好处,比如探索大脑的灵敏度对任何生物参数,也是一个系统的路径识别所有的弱点在大脑中;疾病机制和可能的干预的目标。药物靶分子,所以我们需要模型,包含分子如果我们希望能够测试和设计药物在网上。
模拟神经科学也很重要,因为它挑战现状。例如,许多神经科学家仍然认为之前我们首先需要衡量一切试图建立一个大脑在计算机,即使信息理论长期以来一直向我们表明,当有相互依赖关系数据,然后可以有效预测缺失的数据。也许我们需要回答最重要的问题是所有数据的多少对大脑可以预测。有这么多的测量,和实验神经科学是非常昂贵的,所以我们应该测量主要是那些方面真的是无法预测的。
RM:如何在网上模型和再现性改善生物医学科学的斗争吗?
嗯:神经科学是由缺乏严重阻碍了再现性。一些研究表明,多达70%的神经科学测量没有和/或无法复制。自世界每年花费数十亿美元来理解大脑疾病,我们都应该非常非常担心这个问题。今天,模拟神经科学是我们能想到的唯一方式,可以系统地测试所有报告数据的重现性。测试数据是否好最好的办法就是使用它;尝试和构建。快速数据显示的缺陷。在实践中,我们发现没有地面真值测量实验。这令人震惊,我作为一个实验神经学家。实验测量数据经常变化太多依赖作为单独的测量。 For example, a measurement such as the branching pattern of a particular neuron often varies more across laboratories than across species. The number of neurons in a brain region reported by different laboratories can vary more than 10 times.
然而,一个人可以近似地真理通过结合不同类型的数据。如果一个同时考虑所有的测量报告特定类型的数据(例如,数量的神经元在一个特定的大脑区域)和其他不同类型的测量数据(例如突触的数量报告的另一个实验室相同的大脑区域),那么它们之间的相互联系制约是可能的。两个测量相关,因为神经元形成突触,如果一项研究报告数量的神经元也意味着应该有几个突触的另一项研究发现。这种方法的应用多维约束正交数据集变得更加精细和可以应用到许多不同类型的数据。作为一个实验物理学家,我发现它,而深刻的预测比实验测量可以更准确的测量。随着这一发现变得广为人知,它将变得更加明显,为什么一个相互作用实验和模拟神经科学理解大脑是如此重要。
RM: 2018年,你宣布一个新的超级计算机,蓝脑5。这样的HPC系统如何利用项目吗?
嗯:蓝脑5是一个超级计算机由惠普企业(HPE),定制的为我们解决很多不同的数学运算时我们必须运行构建、模拟、可视化和分析数字拷贝的脑组织,并最终整个大脑。
蓝色大脑中的神经元建模一个人今天需要解决约20000常微分方程。整个大脑区域建模时,我们需要解决大约1000亿方程在每个时间步的仿真(四十分之一毫秒)。
模拟并不是唯一的超级计算任务。数字化建设超级计算机的大脑是一个重大的挑战。例如,在一个针头大小的大脑的一部分,大约有十亿点的树枝神经元彼此接触。我们需要找到那些触动,然后生物规则适用于每一个触点来决定如果这就是一个突触可以形成突触的突触或不是基于原理的形式。大部分的接触点并不会形成突触,所以最终大约4000万个接触点,突触形成。执行此计算花了我们两周在2005年的第一台超级计算机,但今天需要秒,我们可以扩展这个上万亿,数以万亿计的接触点在我们最新的超级计算机。
可视化和分析还需要不同种类的超级计算机体系结构。HPE的使用;他们一起把异构计算架构密切符合所有不同的工作负载。

