

快速计算药物靶亲和力与机器学习
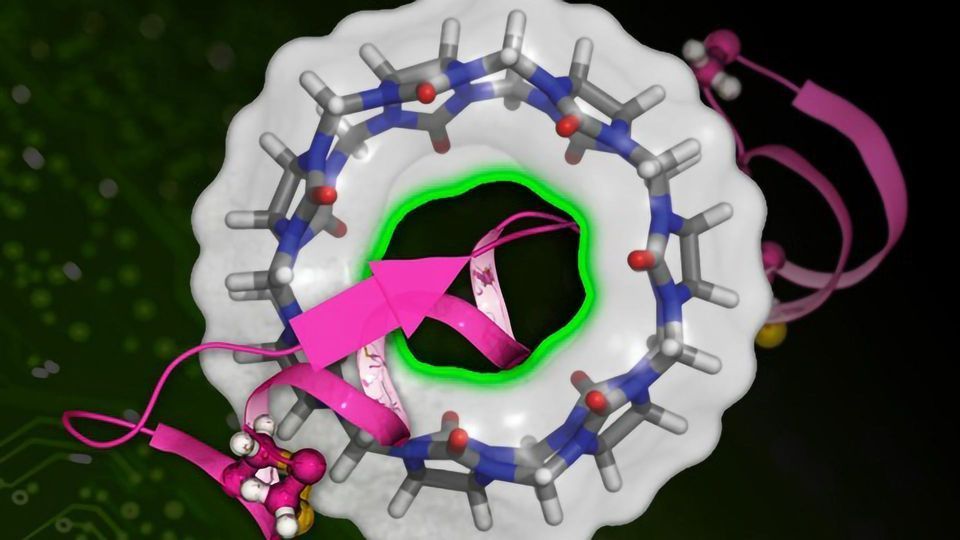
麻省理工学院的研究人员开发了一种基于机器学习技术更快地计算一个药物分子的亲和力(粉红色代表)与靶蛋白(循环结构)。来源:麻省理工学院的新闻,Xinqiang叮和本章
阅读时间:
药物只能工作,如果他们坚持自己的目标蛋白质在体内。评估,粘性是一个关键的障碍在药物发现和筛选过程。新的研究结合化学和机器学习可以降低这一障碍。
这项新技术,被称为强肋骨,快速计算药物之间的结合亲和力候选人和他们的目标。收益率的方法精确计算的一小部分时间比以前先进的方法。研究人员说强肋骨可以加快药物发现和蛋白质工程。
“我们的方法是数量级的速度比以前更快了,这意味着我们可以高效和可靠的药物发现,”本说张Pfizer-Laubach职业发展在麻省理工学院的化学教授,副教授广泛的麻省理工学院和哈佛大学的成员,和描述技术的一篇新论文的作者之一。
这项研究刊登在今天物理化学快报》杂志上。该研究的主要作者是Xinqiang叮,在麻省理工学院化学系博士后。
药物分子之间的亲和力和目标蛋白测量由一个名为结合自由能的数量,数量越小,更棘手的绑定。“结合自由能较低意味着药物能更好地与其他分子竞争,”张先生说,“这意味着它可以更有效地破坏蛋白质的正常功能。”Calculating the binding free energy of a drug candidate provides an indicator of a drug's potential effectiveness. But it's a difficult quantity to nail down.
结合自由能计算方法分为两大类,每个都有自己的缺点。一类计算确切的数量,占用大量的时间和计算机资源。第二类不计算昂贵,但收益率只有一个近似的结合自由能。张和丁发明了一种方法来得到两全其美。
准确和高效
强肋骨结合自由能计算准确,但它只需要一小部分之前要求的计算方法。这项新技术结合了传统的化学计算和机器学习的最新进展。
“酒吧”强肋骨代表“贝内特的接受率,”一个几十年的算法用于绑定的准确计算自由能。班纳特使用承兑比率通常需要两个“端点”国家的知识(例如,一个药物分子绑定到蛋白质和药物分子完全分离的蛋白质),加上中间许多州的知识(例如,不同程度的部分绑定),所有这些陷入困境的计算速度。
班纳特强肋骨斜杠中间状态的部署在机器学习框架称为深的接受率生成模型。“这些模型创建一个引用每个端点、束缚态和游离状态,”张先生说。这两个参考国家足够相似,班尼特接受比率可以直接使用,无需昂贵的中间步骤。
在使用深生成模型,研究人员借用计算机视觉领域。“这基本上是相同的模型,人们使用计算机图像synthensis,”张表示。“我们对待每一个分子结构图像,该模型可以学习。这个项目是建立在机器学习社区的努力。”
在计算机视觉的方法适应化学强肋骨的关键创新、交叉也提出了一些挑战。“这些模型最初开发的2 d图像,”丁说。“但是这里有蛋白质和分子——这是一个真正的三维结构。因此,采用这些方法在我们的案例中是最大的技术挑战我们必须克服。”
药物筛选更快的未来
在测试中使用小分子蛋白质像,强肋骨结合自由能计算近50倍的速度比先前的方法。张医生说,效率意味着“我们可以真正开始考虑使用这种药物筛选,特别是Covid的上下文中。强肋骨具有相同精度的黄金标准,但它是快得多。”The researchers add that, in addition to drug screening, DeepBAR could aid protein design and engineering, since the method could be used to model interactions between multiple proteins.
强肋骨是“一个非常好的计算工作”有几个障碍清除之前,可以用在实际药物发现,迈克尔说Gilson制药科学教授在加州大学圣地亚哥,他并没有参与这项研究。他说强肋骨需要对复杂的实验数据进行验证。”,肯定会带来增加了挑战,而且可能需要添加进一步逼近。”
在未来,研究人员计划改善强肋骨运行计算大型蛋白质的能力,一个任务可行由计算机科学的最新进展。“这项研究是传统的计算化学方法相结合的一个例子,发展了几十年,机器学习的最新发展,”丁说。“所以,我们之前的东西是不可能实现了。”
参考: 丁张X和b强肋骨:快速、准确的结合自由能计算方法。 期刊。化学。列托人。 2021;12:2509 - 2515。doi: 10.1021 / acs.jpclett.1c00189
本文从以下转载材料。注:材料可能是长度和内容的编辑。为进一步的信息,请联系引用源。
广告

